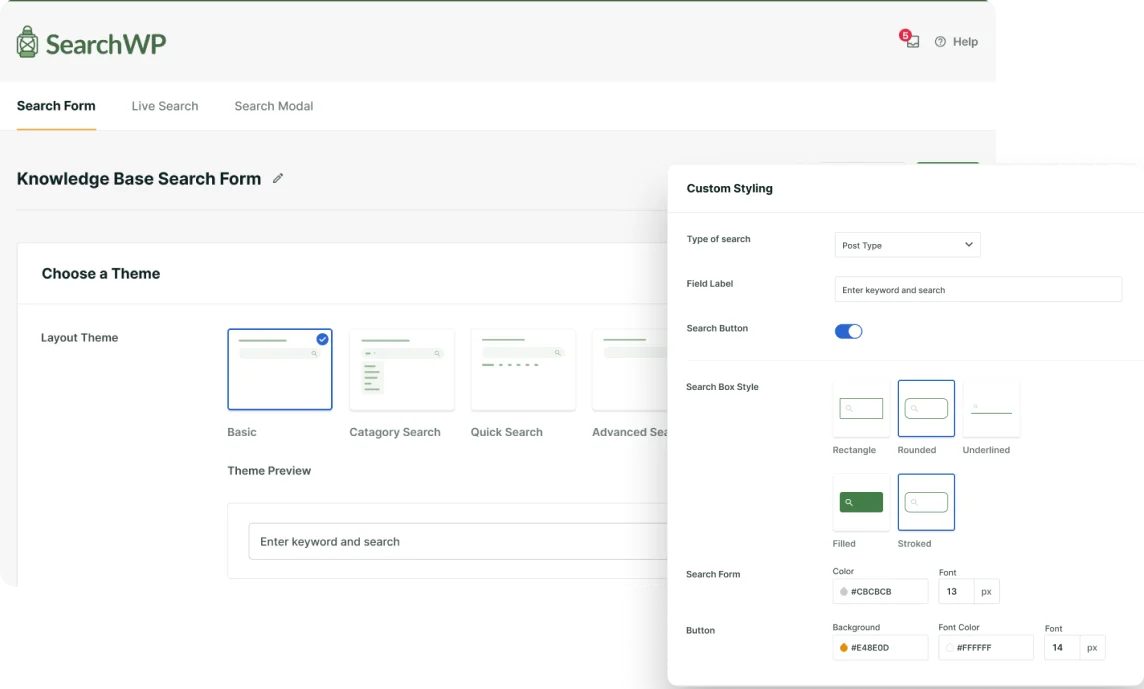


Add a modal form like this to your site with SearchWP’s Modal Search Form Extension!
Searching PDF, Office, and Text Documents
When finding the most relevant search results, it’s important to consider data beyond the Title, Content, and Excerpt which is the only thing native WordPress includes.
In addition to searching Custom Fields and Taxonomy Terms (and providing results based on relevancy) SearchWP also takes into consideration the Media you’ve uploaded to your site.
Many times the images uploaded to your entries include alt text, filenames with valuable keywords, and more for example.
SearchWP will also parse your documents and make that content searchable as well! Supported document types include PDFs, Office documents, plain (and rich) text, and more!
WordPress is able to display results from your Media library in the same way it displays results from any other post type, and SearchWP is able to find documents added to your Media library!
Adding document content to search results
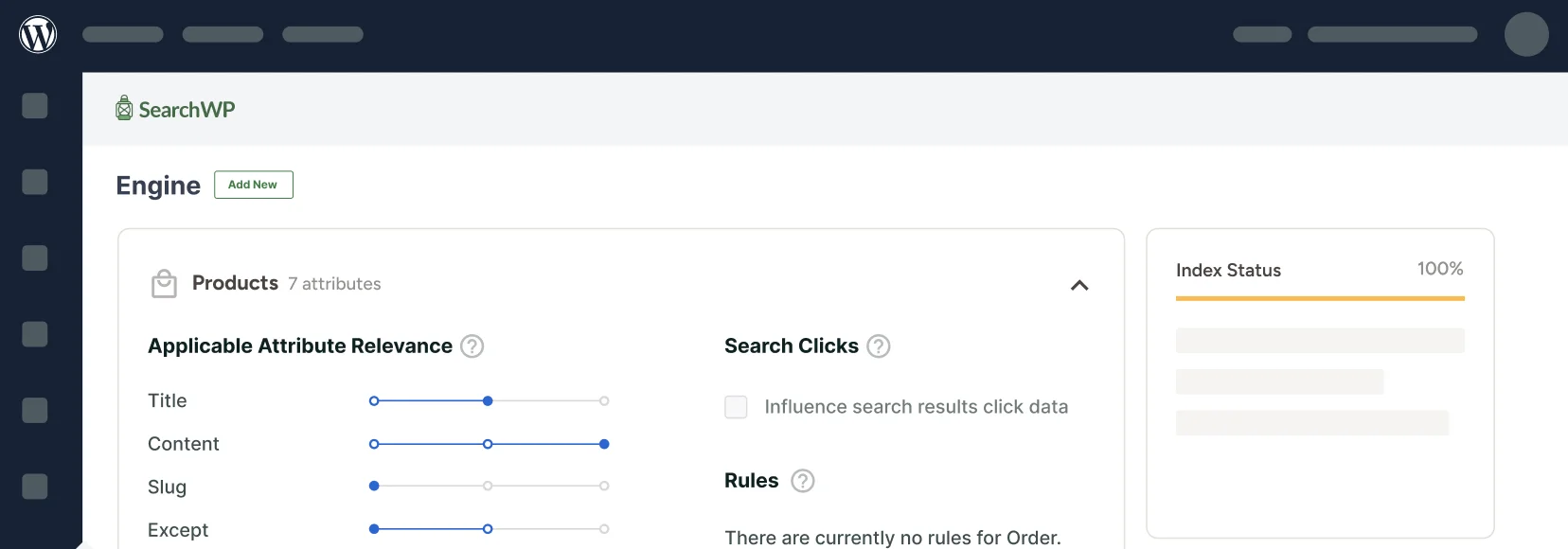
Adding document content to SearchWP is a matter of adding the Document Content attribute to Media within a SearchWP Engine:

With that in place you can set the relevancy weight to Document Content and SearchWP will extract content from documents within your Media library and index that content along with everything else that’s been added to the Engine.
SearchWP also allows you to quickly restrict Media results based on file type by taking advantage of Rules:

How do Media results appear?
SearchWP does not modify the way your theme displays search results in any way.
Media (as far as WordPress and SearchWP is concerned) is just another post type entry that has a permalink, Title, and other details that your search results include.
SearchWP’s job is to find those Media results and include them when applicable, your theme will display a Media result in the same way it does any other post type result.
Find out more
To learn more about how SearchWP fixes WordPress search, have a look at the following:
Create a Better WordPress Search Experience Today
Never lose visitors to unhelpful search results again. SearchWP makes creating your own smart WordPress search fast and easy.
Get SearchWP Now